The AI hype is based on the assumption that the frontier AI labs are producing better and better foundational models at an accelerating pace. Is that really true, or are people just in sort of a mass psychosis because AI models have become so good at mimicking human behavior that we unconsciously attribute increasing intelligence to them? I decided to conduct a mini-benchmark of my own to find out if the latest and greatest AI models are actually really good or not.
The problem with benchmarks
Every time any team releases a new LLM, they boast how well it performs on various industry benchmarks such as Humanity’s Last Exam, SWE-Bench and Ai2 ARC or ARC-AGI. An overall leaderboard can be viewed at LLM-stats. This incentivizes teams to optimize for specific benchmarks, which might make them excel on specific tasks while general abilities degrade. Also, the older a benchmark dataset is, the more online material there is discussing the questions and best answers, which in turn increases the chances of newer models trained on more recent web content scoring better.
Thus I prefer looking at real-time leaderboards such as the LM Arena leaderboard (or OpenCompass for Chinese models that might be missing from LM Arena). However, even though the LM Arena Elo score is rated by humans in real-time, the benchmark can still be played. For example, Meta reportedly used a special chat-optimized model instead of the actual Llama 4 model when getting scored on the LM Arena.
Therefore I trust my own first-hand experience more than the benchmarks for gaining intuition. Intuition however is not a compelling argument in discussions on whether or not new flagship AI models have plateaued. Thus, I decided to devise my own mini-benchmark so that no model could have possibly seen it in its training data or be specifically optimized for it in any way.
My mini-benchmark
I crafted 6 questions based on my own experience using various LLMs for several years and having developed some intuition about what kinds of questions LLMs typically struggle with.
I conducted the benchmark using the OpenRouter.ai chat playroom with the following state-of-the-art models:
- Claude Opus 4.6 (Anthropic)
- GPT-5.2 (OpenAI)
- Grok 4.1 (xAI)
- Gemini 3.1 Pro Preview (Google)
- GLM 5 (Z.ai)
- MinMax M2.5 (MinMax)
- Qwen3.5 Plus 2026-02-15 (Alibaba)
- Kimi K2.5 (Moonshot.ai)
OpenRouter.ai is great as it very easy to get responses from multiple models in parallel to a single question. Also it allows to turn off web search to force the models to answer purely based on their embedded knowledge.
Common for all the test questions is that they are fairly straightforward and have a clear answer, yet the answer isn’t common knowledge or statistically the most obvious one, and instead requires a bit of reasoning to get correct.
Some of these questions are also based on myself witnessing a flagship model failing miserably to answer it.
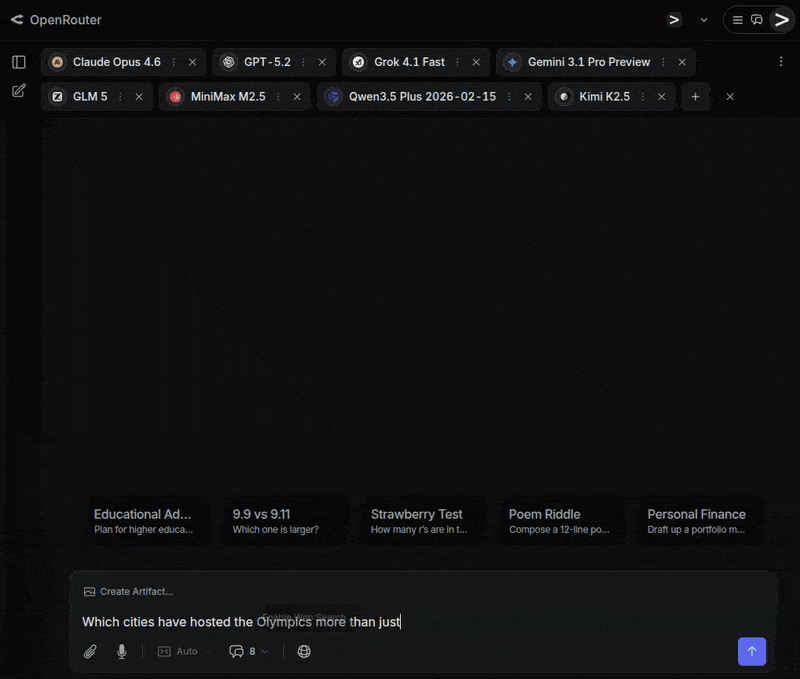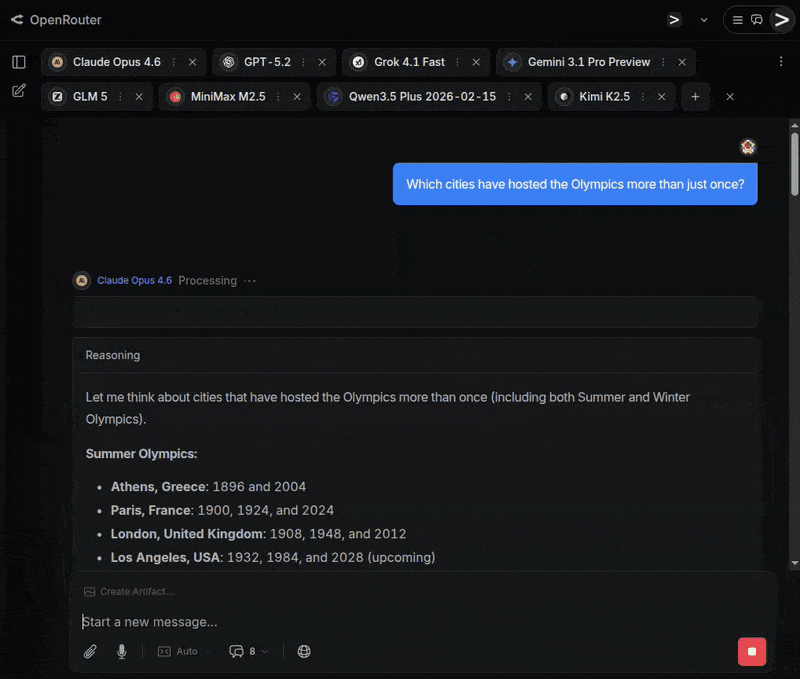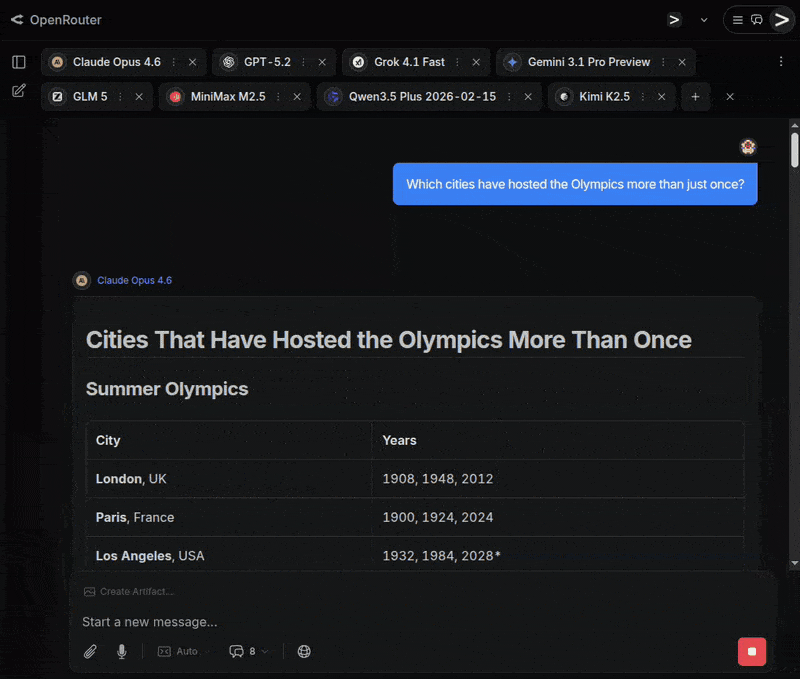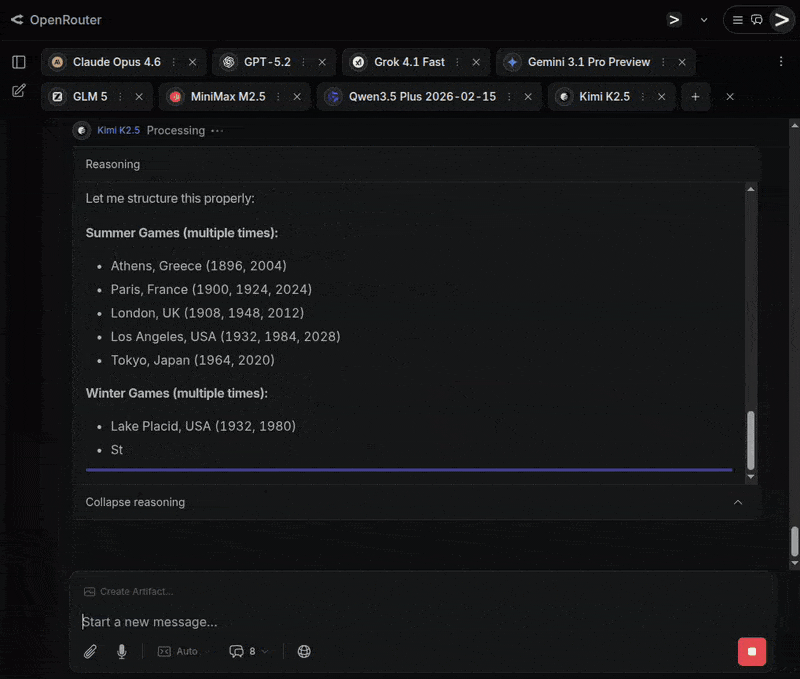
1. Which cities have hosted the Olympics more than just once?
This question requires accounting for both summer and winter Olympics, and for Olympics hosted across multiple cities.
The variance in responses comes from if the model understands that Beijing should be counted as it has hosted both summer and winter Olympics. Interestingly GPT was the only model to not mention Beijing at all. Some variance also comes from how models account for co-hosted Olympics. For example Cortina should be counted as having hosted the Olympics twice, in 1956 and 2026, but only Claude, Gemini and Kimi pointed this out. Stockholm’s 1956 hosting of the equestrian games during the Melbourne Olympics is a special case, which GPT, Gemini and Kimi pointed out in a side note. Some models seem to have old training material, and for example Grok assumes the current year is 2024. All models that accounted for awarded future Olympics (e.g. Los Angeles 2028) marked them clearly as upcoming.
Overall I would judge that only GPT and MinMax gave incomplete answers, while all other models replied as the best humans could reasonably have.
2. If EUR/USD continues to slide to 1.5 by mid-2026, what is the likely effect on BMW’s stock price by end of 2026?
This question requires mapping the currency exchange rate to historic value, dodging the misleading word “slide”, and reasoning on where the revenue of a company comes from and how a weaker US dollar affects it in multiple ways. I’ve frequently witnessed flagship models get it wrong how interest rates and exchange rates work. Apparently the binary choice between “up” or “down” is somehow challenging to the internal statistical model in the LLMs on a topic where there are a lot of training material that talk about both things being likely to happen, and choosing between them requires specifically reasoning about the scenario at hand and disregarding general knowledge of the situation.
However, this time all the models concluded correctly that a weak dollar would have a negative overall effect on the BMW stock price. Gemini, GLM, Qwen and Kimi also mention the potential hedging effect of BMW’s X-series production in South Carolina for worldwide export.
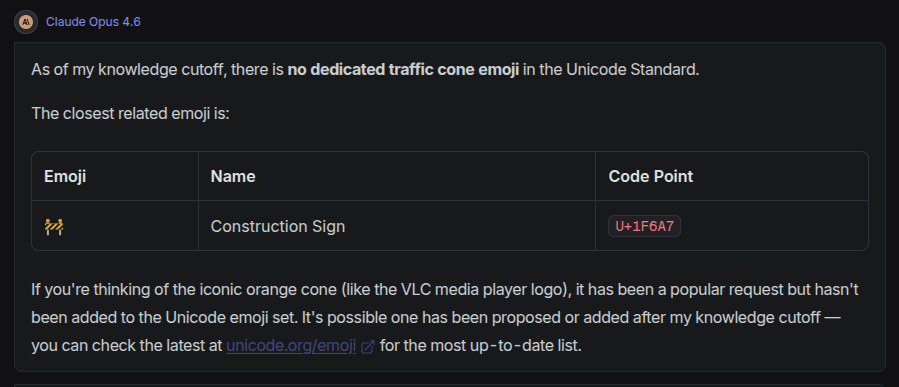
3. What is the Unicode code point for the traffic cone emoji?
This was the first question where the the flagship models clearly still struggle in 2026. The trap here is that there is no traffic cone emoji, so an advanced model should simply refuse to give any Unicode numbers at all. Most LLMs however have an urge to give some answer, leading to hallucinations. Also, as the answer has a graphical element to it, the LLM might not understand how the emoji “looks” in ways that would be obvious to a human, and thus many models claim the construction sign emoji is a traffic cone, which it is not.
By far the worst response was from GPT, that simply hallucinates and stops there:

While Gemini and Grok were among the three models not falling into this trap, the response from Claude was exemplary good:
4. Which languages are the 10 most commonly spoken in the world? For each language, count from 1 to 5.
This seemingly simple question can become quite complex when you account for the fact that other languages might also have their own character system, both for words and the numerals (e.g. Arabic واحد/one vs ١/1), and that numbers might have variations depending on what the thing being counted is (e.g in French object gender un/une), or whether plain numbers and occurrences have their own words (e.g. Russian один/odin vs раз/raz). I’ve also witnessed older models frequently mix up on what parts of the reply should be using what language.
For a human this question is trivial, assuming they know the language. For LLMs it is surprisingly challenging. Grok and MinMax only gave a list of the most popular languages and stopped there without showing any words in the languages. Qwen got a bit further by trying to list numbers in each language, but the lists were only the numbers 1 to 5:
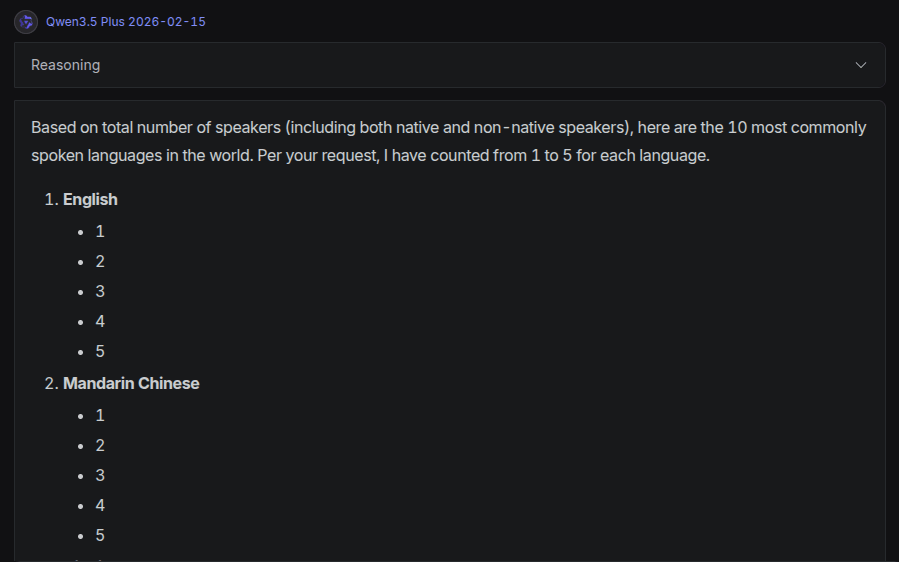
I have seen Grok do something similar before, which in fact inspired me to include this question in my mini-benchmark.
GPT got a bit further, but for Hindi, Arabic and Bengali it listed the numerals in local script, not the number words. Gemini, GLM and Kimi gave a complete and correct answer as a list, while the absolute best answer and presentation was by Claude, that gave the table below:
Claude Opus 4.6
10 Most Commonly Spoken Languages (by Total Speakers)
# Language 1 2 3 4 5 1 English One Two Three Four Five 2 Mandarin Chinese 一 (yī) 二 (èr) 三 (sān) 四 (sì) 五 (wǔ) 3 Hindi एक (ek) दो (do) तीन (tīn) चार (chār) पाँच (pā̃ch) 4 Spanish Uno Dos Tres Cuatro Cinco 5 French Un Deux Trois Quatre Cinq 6 Arabic واحد (wāḥid) اثنان (ithnān) ثلاثة (thalātha) أربعة (arbaʿa) خمسة (khamsa) 7 Bengali এক (ek) দুই (dui) তিন (tin) চার (chār) পাঁচ (pā̃ch) 8 Portuguese Um Dois Três Quatro Cinco 9 Russian Один (odin) Два (dva) Три (tri) Четыре (chetyre) Пять (pyat') 10 Japanese 一 (ichi) 二 (ni) 三 (san) 四 (shi) 五 (go) Note: Rankings are based on estimated total speakers (native + non-native). Rankings can vary depending on the source and methodology used.
5. Count the number of drone launch pads in the picture.
Together with the question, I uploaded this picture:

A human can easily count that there are 10 rows and 30+ columns in the grid, but because the picture resolution isn’t good enough, the exact number of columns can’t be counted, and the answer should be that there are at least 300 launch pads in the picture.
GPT and Grok both guessed the count is zero. Instead of hallucinating some number they say zero, but it would have been better to not give any number at all, and just state that they are unable to perform the task. Gemini gave as its answer “101”, which is quite odd, but reading the reasoning section, it seems to have tried counting items in the image without reasoning much about what it is actually counting and that there is clearly a grid that can make the counting much easier. Both Qwen and Kimi state they can see four parallel structures, but are unable to count drone launch pads.
The absolutely best answer was given by Claude, which counted 10-12 rows and 30-40+ columns, and concluded that there must be 300-500 drone launch pads. Very close to best human level - impressive!
This question applied only to multi-modal models that can see images, so GLM and MinMax could not give any response.
6. Explain why I am getting the error below, and what is the best way to fix it?
Together with the question above, I gave this code block:
$ SH_SCRIPTS="$(mktemp; grep -Irnw debian/ -e '^#!.*/sh' | sort -u | cut -d ':' -f 1 || true)"
$ shellcheck -x --enable=all --shell=sh "$SH_SCRIPTS"
/tmp/tmp.xQOpI5Nljx
debian/tests/integration-tests: /tmp/tmp.xQOpI5Nljx
debian/tests/integration-tests: openBinaryFile: does not exist (No such file or directory)Older models would easily be misled by the last error message thinking that a file went missing, and focus on suggesting changes to the complex-looking first line. In reality the error is simply caused by having the quotes around the $SH_SCRIPTS, resulting in the entire multi-line string being passed as a single argument to shellcheck. So instead of receiving two separate file paths, shellcheck tries to open one file literally named /tmp/tmp.xQOpI5Nljx\ndebian/tests/integration-tests.
Incorrect argument expansion is fairly easy for an experienced human programmer to notice, but tricky for an LLM. Indeed, Grok, MinMax, and Qwen fell for this trap and focused on the mktemp, assuming it somehow fails to create a file. Interestingly GLM fails to produce an answer at all, as the reasoning step seems to be looping, thinking too much about the missing file, but not understanding why it would be missing when there is nothing wrong with how mktemp is executed.
Claude, Gemini, and Kimi immediately spot the real root cause of passing the variable quoted and suggested correct fixes that involve either removing the quotes, or using Bash arrays or xargs in a way that makes the whole command also handle correctly filenames with spaces in them.
Conclusion
| Model | Sports | Economics | Emoji | Languages | Visual | Shell | Score |
|---|---|---|---|---|---|---|---|
| Claude Opus 4.6 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 6/6 |
| GPT-5.2 | ✗ | ✓ | ✗ | ~ | ✗ | ✓ | 2.5/6 |
| Grok 4.1 | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | 3/6 |
| Gemini 3.1 Pro | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | 5/6 |
| GLM 5 | ✓ | ✓ | ? | ✓ | N/A | ✗ | 3/5 |
| MinMax M2.5 | ✗ | ✓ | ✗ | ✗ | N/A | ✗ | 1/5 |
| Qwen3.5 Plus | ✓ | ✓ | ✗ | ~ | ✗ | ✗ | 2.5/6 |
| Kimi K2.5 | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ | 4/6 |
Obviously, my mini-benchmark only had 6 questions, and I ran it only once. This was obviously not scientifically rigorous. However it was systematic enough to trump just a mere feeling.
The main finding for me personally is that Claude Opus 4.6, the flagship model by Anthropic, seems to give great answers consistently. The answers are not only correct, but also well scoped giving enough information to cover everything that seems relevant, without blurping unnecessary filler.
I used Claude extensively in 2023-2024 when it was the main model available at my day work, but for the past year I had been using other models that I felt were better at the time. Now Claude seems to be the best-of-the-best again, with Gemini and Kimi as close follow-ups. Comparing their pricing at OpenRouter.ai the Kimi K2.5 price of $0.6 / million tokens is almost 90% cheaper than the Claude Opus 4.6’s $5.0 / million tokens suggests that Kimi K2.5 offers the best price-per-performance ratio. Claude might be cheaper with a monthly subscription directly from Anthropic, potentially narrowing the price gap.
Overall I do feel that Anthropic, Google and Moonshot.ai have been pushing the envelope with their latest models in a way that one can’t really claim that AI models have plateaued. In fact, one could claim that at least Claude has now climbed over the hill of “AI slop” and consistently produces valuable results. If and when AI usage expands from here, we might actually not drown in AI slop as chances of accidentally crappy results decrease. This makes me positive about the future.
I am also really happy to see that there wasn’t just one model crushing everybody else, but that there are at least three models doing very well. As an open source enthusiast I am particularly glad to see that Moonshot.ai’s Kimi K2.5 is published with an open license. Given the hardware, anyone can run it on their own. OpenRouter.ai currently lists 9 independent providers alongside Moonshot.ai itself, showcasing the potential of open-weight models in practice.
If the pattern holds and flagship models continue improving at this pace we might look back at 2026 as the year AI stopped feeling like a call center associate and started to resemble a scientific researcher. While new models become available we need to keep testing, keep questioning, and keep our expectations grounded in actual performance rather than press releases.
Thanks to OpenRouter.ai for providing a great service that makes testing various models incredibly easy!